

本記事ではGROUPBY関数の基本的な使い方とその応用例について詳しく解説します。
SQLやAccessを利用することで様々なデータ分析ができますが、ExcelのGROUPBY関数を使用するとSQLの「GROUP BY」「WHERE」「ORDER BY」を置き換えることができるため簡単にデータ分析等ができます。
EXCELにはGROUPBY関数の同等機能としてピボットテーブルがありますがGROUPBY関数はデータが変化すると直ぐに出力内容が更新されるためピポットテーブルからGROUPBY関数に置き換え検討できます。
※本記事ではテーブルを前提として記載していますが、テーブルを使わずに列(A1:A10等)を使うことも可能です。

GROUPBY関数の引数
GROUPBY関数は下表の通りです。
| 引数 | 説明 |
|---|---|
| row_fields(必須) | グループ化する列を指定します。(範囲・配列を指定可能) |
| values(必須) | 集計する列を指定します。(範囲・配列を指定可能) |
| function(必須) | 集計方法を指定します (SUM、PERCENTOF、AVERAGE、COUNT など)。(配列を指定可能) |
| field_headers | ヘッダーの表示を制御します。 |
| total_depth | 小計、総計の表示を制御します。 |
| sort_order | 並び替え条件を指定します。 数値が負の場合、行は降順または逆順に並べ替えられます。(配列を指定可能) |
| filter_array | 抽出条件を指定します。AND条件・OR条件の指定および組み合わせが指定可能。 |
| field_relationship | sort_orderと関連する項目。並び替えを制御します。 |
必須引数のみを使った基本の使い方
ここでは必須引数を使った3つの例を説明します。
基本の使い方
グループ化する列、集計する列、集計方法を指定します。
基本的には下記のようにします。
=GROUPBY(Sales[部署]:Sales[氏名],Sales[売上額],SUM)下記の例は[#すべて]を項目名に追加することで後ほど説明するヘッダを表示することができます。このため基本的には[#すべて]を追加した形で表示することをお勧めします。
=GROUPBY(Sales[[#すべて],[部署]],Sales[[#すべて],[売上額]],SUM)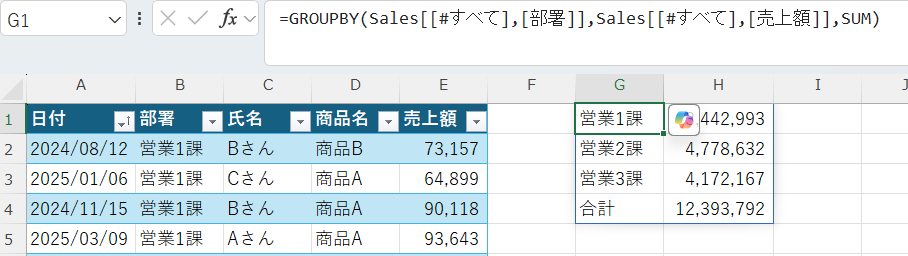
連続した列をグループ化する方法
連続した列をグループ化する場合は下記のように記載します。
=GROUPBY(
Sales[[#すべて],[部署]]:Sales[[#すべて],[部署]],
Sales[[#すべて],[売上額]],
SUM)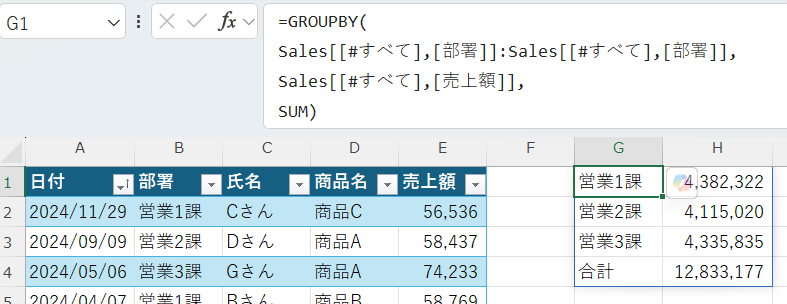
任意の列をグループ化する方法
任意の列や列の順番を変更したい場合は下記のようにHSTACK関数を使い記述します。
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM)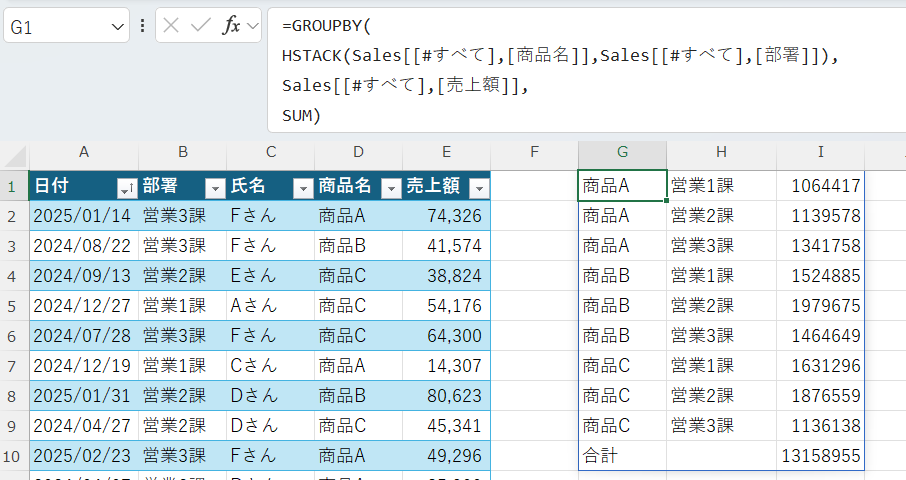
変換後の値をグループ化する方法
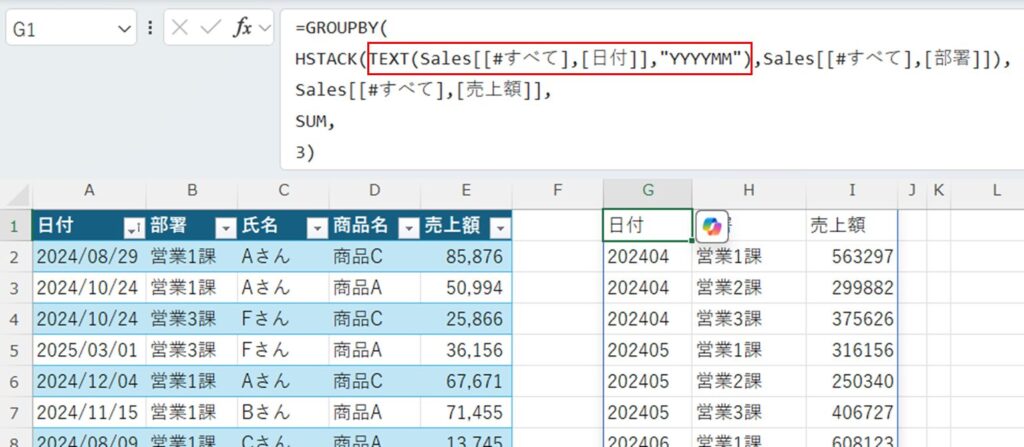
グループ化の指定を単純に列を指定するのではなく値を変換しグループ化することができます。例えば日付の場合、年月に変換しグループ化することで月毎の集計が可能となります。
=GROUPBY(
HSTACK(TEXT(Sales[[#すべて],[日付]],"YYYYMM"),Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM,
3)
第3引数:Function
これまでSUMのみを使ってきましたが他にも下記の値を使えます。
- SUM:合計値
- PERCENTOF:総計からの比率
- AVERAGE:平均値
- MEDIAN:中央値
- COUNT:空白以外の件数
- COUNTA:空白込みの件数
- MAX:最大値
- MIN:最小値
- PRODUCT:乗算
- ARRAYTOTEXT:文字結合。カンマ区切りテキスト
- CONCAT:文字結合
- STDEV.S:標準偏差(標本)
- STDEV.P:標準偏差(母集団全体)
- VAR.S:分散(標本)
- VAR.P:分散(母集団全体)
- MODE.SNGL:最頻値
- LAMBDA:任意の集計方法
複数の集計項目を指定したい場合はHSTACK関数を使います。
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
HSTACK(SUM,AVERAGE))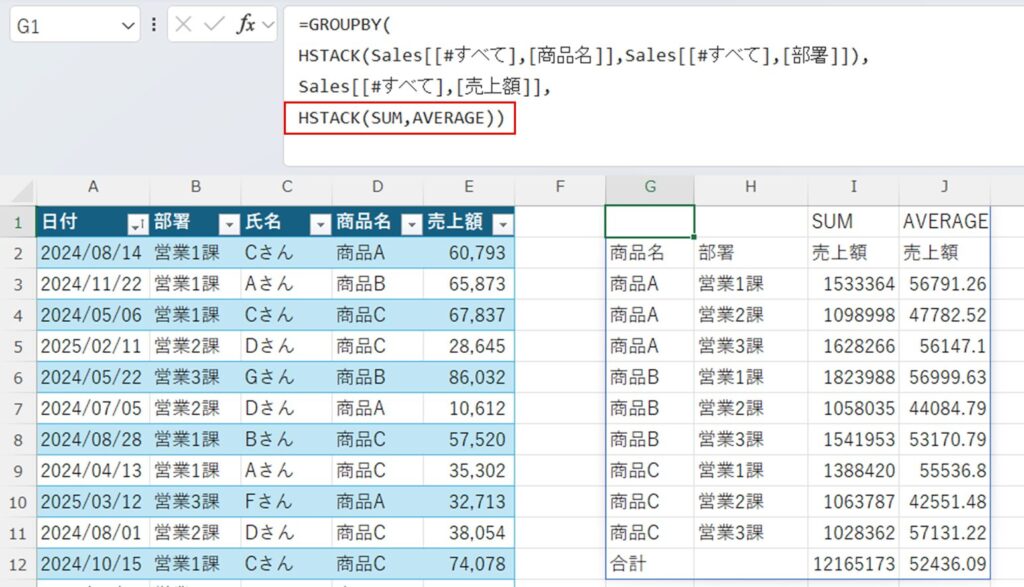
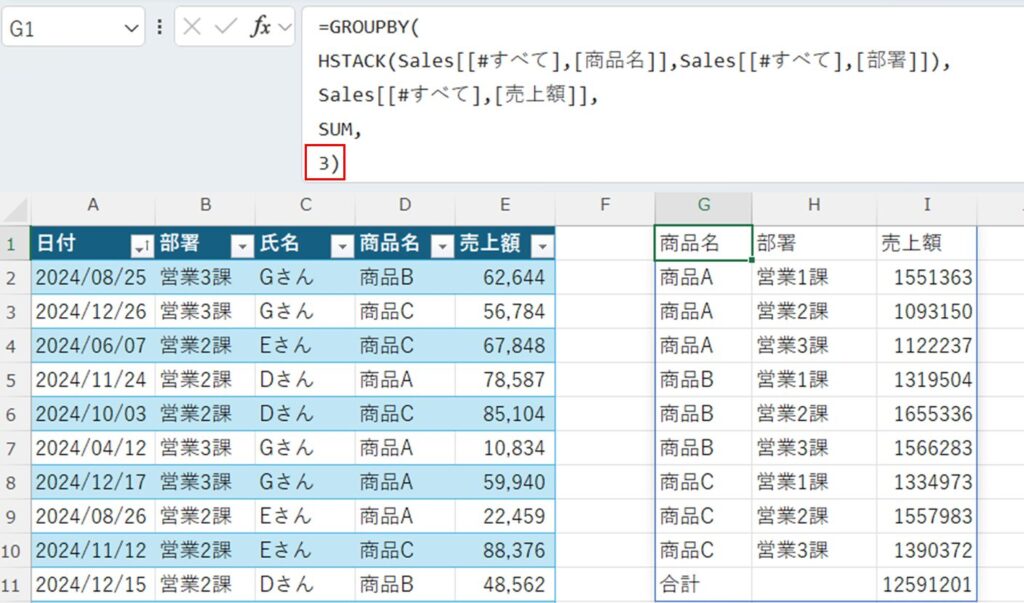
第4引数:field_headers
フィールドヘッダの表示を制御します。基本的には表示したい場合は「3:はい、表示します」を指定すれば問題ありません。
| 値 | ヘッダ表示 |
|---|---|
| 省略 | 自動判別 |
| 0:いいえ | 表示しない |
| 1:はい、表示しません | 表示しない |
| 2:生成しない | 行フィールドX、値X等を表示 |
| 3:はい、表示します | 列名を表示 |
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM,
3)
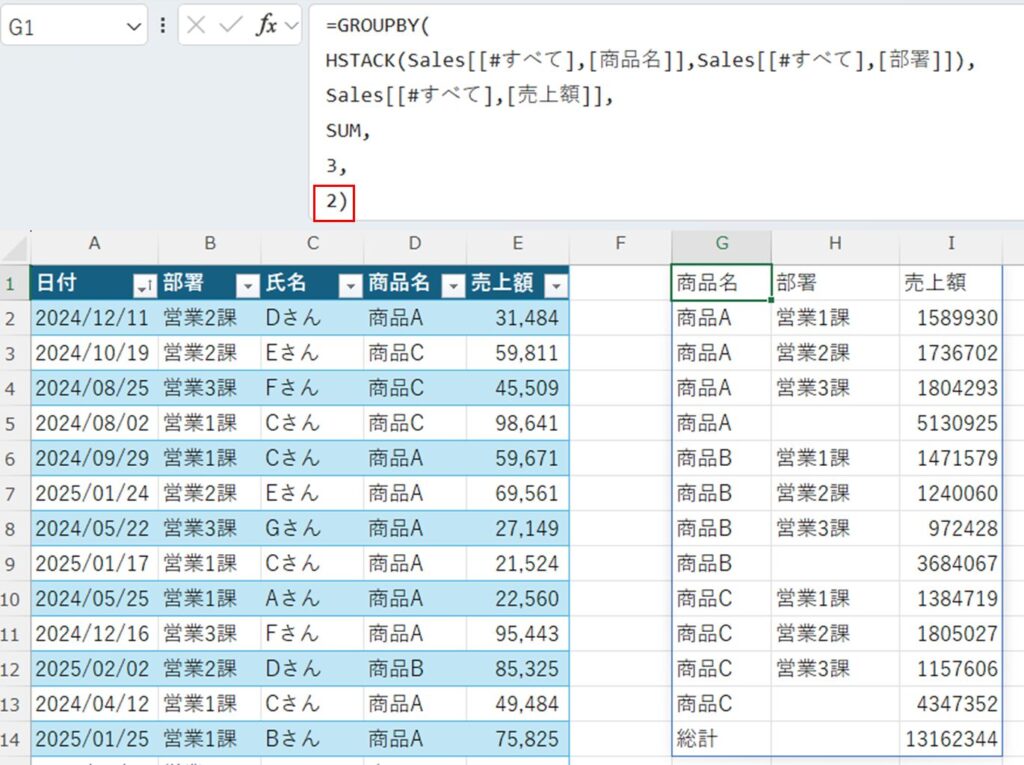
第5引数:total_depth
総計と小計の表示制御を行います。小計を表示する場合は必ずグループ化する列が2つ以上必要です。
| 値 | 説明 |
|---|---|
| 省略 | 自動。総計と可能な場合は小計を表示。 |
| 0:合計なし | 表示しない |
| 1:総計(下) | 総計(明細の下に表示) |
| 2:総計と小計(下) | 総計と小計(明細の下に表示) |
| -1:総計(上) | 総計(明細の上に表示) |
| -2:総計と小計(上) | 総計と小計(明細の上に表示) |
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM,
3,
2)
第6引数:sort_order
行の並べ替え条件を指定します。列番号を指定しますがマイナスを指定することで降順にすることができます。後述の「第8引数:Field_relationship」も関連するため合わせて参照。
基本的な使い方
列番号を指定し昇順で並び替えを行います。マイナスを指定することで降順で並び替えを行います。下記例では-1を指定することで1列目を降順で並べ替えます。
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM,
3,
2,
-1)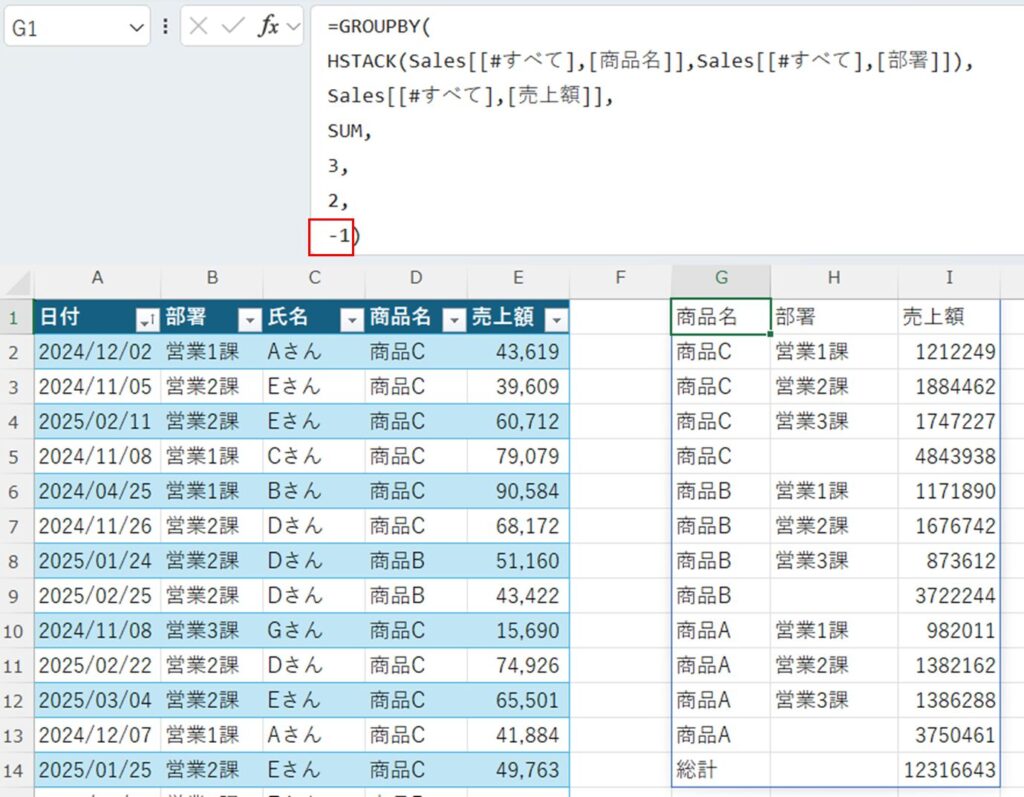
複数の列を指定する方法
並び替え条件を複数指定する方法です。下の例では{-1、-2}を指定することで1列目、2列目を降順で表示する方法です。
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM,
3,
2,
{-1,-2})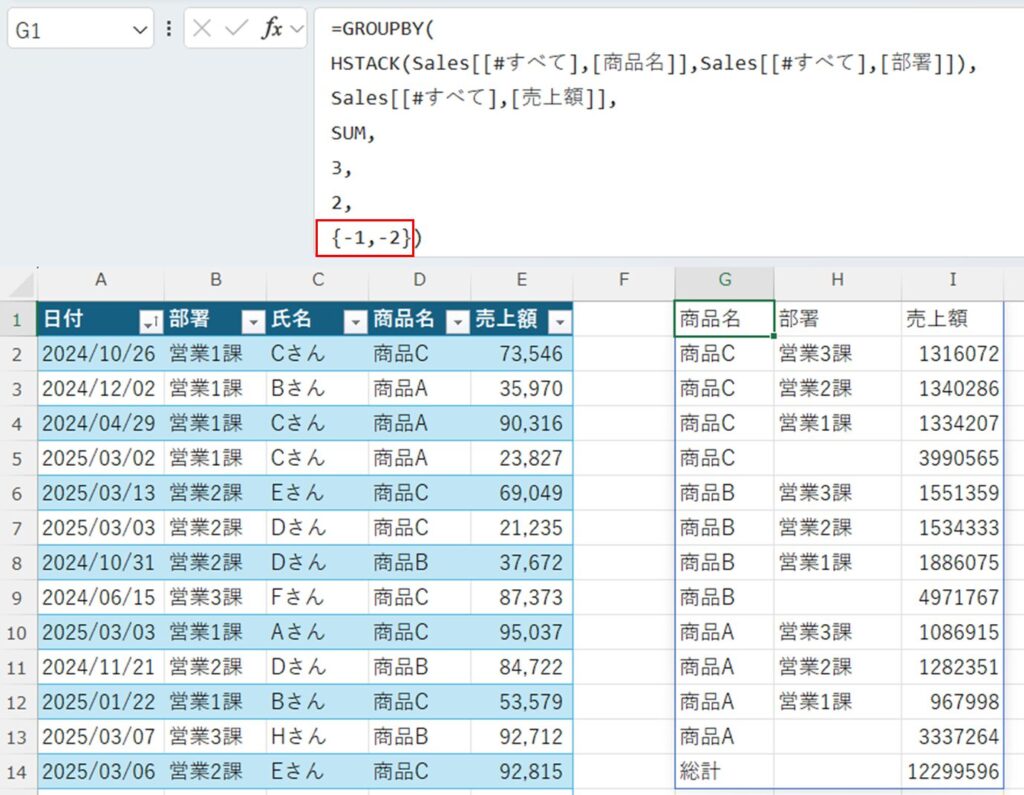
第7引数:filter_array
抽出条件を指定します。複数条件を指定する場合は条件を「()」で囲み「*(かつAND)」または「+(またはOR)」で条件を繋ぎます。
=GROUPBY(
HSTACK(Sales[[#すべて],[商品名]],Sales[[#すべて],[部署]]),
Sales[[#すべて],[売上額]],
SUM,
3,
2,
{-1,-2},
(Sales[部署]="営業2課")*(Sales[商品名]="商品B"))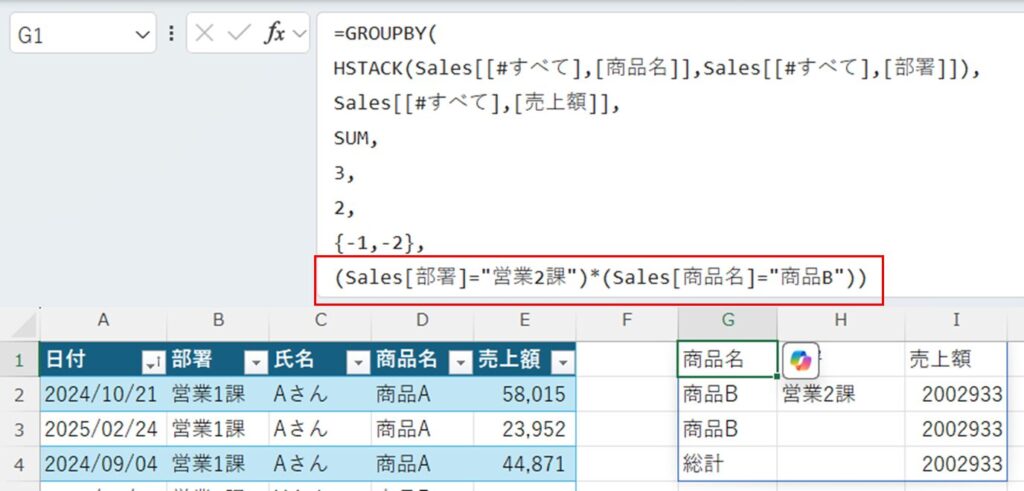
第8引数:Field_relationship
sort_order(並び替え)と関わる引数です。sort_orderが1または-1の場合はこの引数は考えなくてもよいですが、2または-2以上を指定する場合、出力方法が変化します。
下図はsort_orderを2(部署で並び替え)を指定しています。Field_relationshipは左が「0」右が「1」を指定しています。Field_relationship=0の場合は1列目が優先して並び替えされるようです。これを回避するためにField_relationship=1を指定し期待した並び替え条件になります。
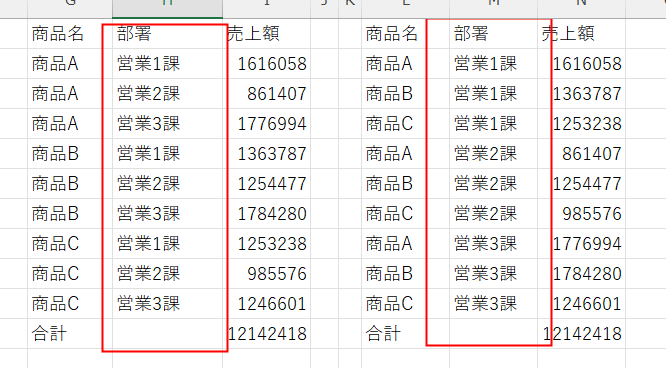
左側の表はField_relationship=0、右側はField_relationship=1









コメント